Conexionismo
Publica tus artículos en conexionismo.com
Tweet
Con este artículo trataremos de dar claridad a la realización e interpretación de una prueba t de Student para dos muestras independientes, mediante cálculo manual, con calculadora y tablas de distribución, y mediante programas de análisis estadístico como Excel y SPSS.
ARTÍCULO: Prueba t de Student para la comparación de dos muestras independientes.
Introducción.
El índice media es probablemente el mas universalmente conocido por personas sin formación en estadística, pero también es uno de los mas usados, quizás por su fácil comprensión. En este artículo vamos a analizar como calcular e interpretar el estadístico t de Student para dos muestras independientes de manera manual, con Excel y por ultimo con SPSS. Complementariamente a este, tenemos tambien publicado un artículo sobre el estadístico t de Student para dos muestras relacionadas. También hemos publicado un nuevo artículo sobre la comparación de más de dos muestras independientes.
Con este artículo vamos a analizar un caso muy frecuente, como es la comparación de medias entre dos muestras independientes. Se considera que dos muestras son independientes cuando no hay una conexión entre la medición de una variable con la medición de la otra.
Para ilustrar este caso, planteamos el siguiente ejemplo (archivo de referencia: datos_ejemplo_inferencia.xls):
Las universidades A y B se preguntan si el nivel formativo en estadística de una y otra universidad es diferente. Para tratar de dar respuesta a esta pregunta, someten a 75 alumnos de cada universidad elegidos al azar a un mismo examen. Las calificaciones de los alumnos de cada universidad pueden verse en las columnas A y B respectivamente de este archivo (enlace).
Supuestos del modelo t de Student para dos muestras independientes.
Nivel de medida de las variables: métricas, es decir, intervalo o razón.
Distribución: normal o aproximadamente normal.
Tipo de diseño: equilibrado o no equilibrado.
Varianzas poblacionales: desconocidas, supuestamente iguales o sin supuesto de igualdad.
Observaciones: aleatorias e independientes.
Hipótesis que se somete a prueba: la diferencia entre las dos medias toma un determinado valor, generalmente cero.
Bondad de ajuste.
La bondad de ajuste de un conjunto de datos hace referencia a las propiedades que debe poseer ese conjunto de datos en función del modelo inferencial que se pretende utilizar.
En el caso de del estadístico t para dos muestras independientes, como ya se dijo antes, los supuestos son: distribución normal o aproximadamente normal, y conocer si las varianzas poblacionales pueden ser o no asumidas iguales.
Para conocer la normalidad de las distribuciones, emplearemos la prueba de Kolmogorov-Smirnov, los resultados pueden verse en la tabla 1.
Tabla 1: Resultados de SPSS para la prueba de Kolmogorov-Smirnov.
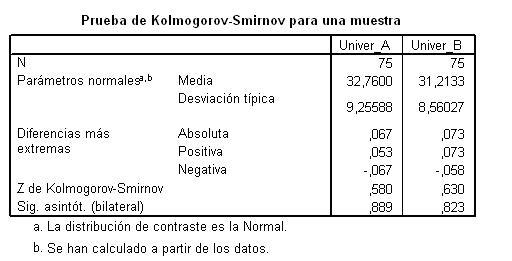
Como puede verse, la significación estadística del estadístico de Kolmogorov-Smirnov es de 0,889 para la universidad A y de 0,823 para la universidad B. Dado que la probabilidad del estadístico de contraste es elevada, muy por encima de 0,05, podemos aceptar que ambas muestras se distribuyen normalmente.
Para saber si las varianzas poblacionales son estadísticamente iguales o no emplearemos la prueba F para varianzas de dos muestras, Excel tiene una función con el nombre de “Prueba F para varianzas de dos muestras” en “Herramientas à Análisis de datos*”. Los resultados pueden verse en la tabla 2.
Tabla 2: Resultados de la prueba F de homogeneidad de varianzas mediante Excel.
|
Prueba F para varianzas de dos muestras
|
||
|
|
|
|
|
|
Variable 1
|
Variable 2
|
|
Media
|
32,76
|
31,2133333
|
|
Varianza
|
85,6713514
|
73,2781982
|
|
Observaciones
|
75
|
75
|
|
Grados de libertad
|
74
|
74
|
|
F
|
1,1691247
|
|
|
P(F<=f) una cola
|
0,2515966
|
|
|
Valor crítico para F (una cola)
|
1,46945101
|
|
Dado que el estadístico F = 1,169 por tanto menor que el valor critico = 1,469 y que la probabilidad de estadístico 0,2515 es superior a 0,05, podemos asumir que las varianzas no presentan diferencias estadísticamente significativas.
Hipótesis y estadístico de contraste.
Tabla 3: Hipótesis y estadístico de contraste.

Como puede verse en la tabla 3, las hipótesis se establecen en torno a la diferencia de medias. Si asumimos que la diferencia es 0 (es el supuesto mas común), estamos admitiendo que las medias son iguales, si admitiésemos que la diferencia fuese 1, la decisión se tomaría en base a esa diferencia.
Por otro lado, el calculo del estadístico T no tiene mayor complicación, solo restar la diferencia de medias que deseamos contrastar (en la formula el valor es 0). Sobre el error típico de la diferencia de medias, resulta algo más laborioso su cálculo, pero no tiene mayor complicación. Hay que prestar atención a que el calculo de este error se basa en la varianza poblacional, que la estimaremos mediante su estimador insesgado, que es la varianza insesgada de la muestra.
Error, y valores críticos.
Una vez que sabemos que estadístico de contraste vamos a empelar, el siguiente paso es la elección de un nivel de error tipo I o alpha, en términos generales recomendaremos un 5%, no obstante, este valor debe estar supeditado al contexto de cada investigación. La disminución del error tipo I supone que es mas fácil aceptar la hipótesis nula, pero también nos llevara a la aceptación de una hipótesis nula que en realidad es falsa (error tipo II).
Considerando adecuado un error alpha de 0,05 (5%), y dado que no se especifica un sentido para el contraste, asumimos que se trata de un contraste bilateral. Por tanto los valores críticos, es decir, la delimitación de la región de aceptación de la hipótesis nula y la región critica (o de rechazo de la hipótesis nula) en una distribución t de Student bilateral con un alpha de 0,05 y 150-2=148 grados de libertad esta comprendida entre los valores críticos -1,976 y 1,976 (dado que la t de Student es una distribución simétrica). Estos valores tienen una probabilidad asociada de 0,025 (0,05/2) y 0,975 (1-(0,05/2)) respectivamente. Estos valores críticos han sido calculados mediante la función de Excel DISTR.T.INV(ALPHA;GRADOS LIBERTAD), Por tanto aceptaremos la hipótesis nula si -1,976 < t < 1,976, es decir, los valores de t mayores de -1,976 y menores de 1,976 permitirán la aceptación de la hipótesis nula.
Si no tenemos a mano un ordenador con Excel también podemos llegar a una aproximación mediante una tabla de la distribución t de Student. Dado que nuestra tabla solo alcanza los 30 grados de libertad, usaremos la aproximación de tendencia al infinito dado que en nuestro caso tenemos 148 grados de libertad, y puesto que nuestra tabla solo ofrece la mitad derecha de la distribución, usaremos la columna de probabilidad 0,975 (1-(0,05/2)). Según esta tabla 1,96 es el valor crítico correspondiente a la mitad derecha de la distribución, por tanto, dado que la t de Student es simétrica, el valor correspondiente a la mitad izquierda seria -1,96. Así la región de aceptación (según la tabla de la t de Student) estaría comprendida entre los valores de t mayores de -1,96 y menores de 1,96.
Cálculo del estadístico t de Student para dos muestras independientes.
Una vez que sabemos que las muestras se distribuyen normalmente y que las varianzas poblacionales son estadísticamente iguales, podemos proceder al cálculo del estadístico t de Student. Lo primero que necesitamos es conocer los valores de media y varianza insesgada y el tamaño muestral de ambas muestras:
|
|
Univer A
|
Univer B
|
|
Media
|
32,76
|
31,2133333
|
|
Varianza poblac.
|
85,6713514
|
73,2781982
|
|
n
|
75
|
75
|
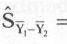
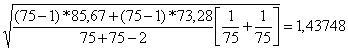
Decisión sobre el estadístico obtenido en función de la región donde se encuentra.
Dado que T = 1,07619 y que es mayor que -1,976 y menor que 1,976 se encuentra dentro de la región de aceptación de la hipótesis nula, aceptamos la hipótesis nula . Por tanto, y dado que la hipótesis nula establecía que la diferencia de medias era igual a 0, podemos concluir que no existe evidencia en contra de que las medias de las dos muestras sean iguales, o lo que es lo mismo, no se han encontrado diferencias estadísticamente significativas.
La conclusión es idéntica para el caso de la región de aceptación delimitada mediante los datos de la tabla de la t de Student (1,96). Solo cabe añadir que el valor que nos da la tabla es menos preciso que el que nos da Excel (1,976). Por tanto, siempre que sea posible usaremos un programa informático (Excel u otro) en lugar de una tabla, dada la precisión que nos ofrece.
Cálculo del estadístico t de Student para dos muestras independientes con Excel.
Para realizar un contraste t de Student para dos muestras independientes con Excel podemos usar las herramientas de análisis de datos que este programa posee para tal efecto. En la versión de Excel 2003, las herramientas de análisis de datos las puede encontrar en el menú Herramientas à Análisis de datos*. Seleccione la prueba t suponiendo varianzas iguales, y cumplimente los datos requeridos. El resultado para el problema que estamos trabajando es el siguiente:
|
Prueba t para dos muestras suponiendo varianzas iguales
|
|||
|
|
|
|
|
|
|
Variable 1
|
Variable 2
|
|
|
Media
|
32,76
|
31,2133333
|
|
|
Varianza
|
85,6713514
|
73,2781982
|
|
|
Observaciones
|
75
|
75
|
|
|
Varianza agrupada
|
79,4747748
|
|
|
|
Diferencia hipotética de las medias
|
0
|
|
|
|
Grados de libertad
|
148
|
|
|
|
Estadístico t
|
1,06242359
|
|
|
|
P(T<=t) una cola
|
0,14488697
|
|
|
|
Valor crítico de t (una cola)
|
1,65521451
|
|
|
|
P(T<=t) dos colas
|
0,28977394
|
|
|
|
Valor crítico de t (dos colas)
|
1,97612246
|
|
|
En este caso la aceptación de la hipótesis nula estará en función de la probabilidad del estadístico. Podemos ver como el estadístico t = 1,0624 no coincide exactamente con el calculado de manera manual, esto se debe a que los programas estadísticos emplean muchos mas decimales en los cálculos de los que se emplean cuando se usa una calculadora. Además esta tabla de resultados también nos ofrece la probabilidad del estadístico, es decir, el valor p o p-valor, que en el caso bilateral (dos colas) toma el valor 0,28977. Cuando este valor toma una probabilidad superior a 0,025 (0,05/2=0,025), asumimos que el estadístico no esta debido al azar, por tanto, podemos aceptar la hipótesis nula que afirma que las diferencias entre las medias es igual a cero. También nos ofrece el valor critico de la mitad derecha de la distribución, tanto para prueba unilateral (una cola), como bilateral (dos colas). Podemos ver como este valor coincide con el calculado mediante la función DISTR.T.INV(ALPHA;GRADOS LIBERTAD) también de Excel. El valor de la mitad izquierda de la distribución es el mismo pero en negativo, es decir, -1,976 puesto que la distribución t de Student es simétrica.
Cálculo del estadístico t de Student para dos muestras independientes con SPSS.
El programa de análisis estadístico SPSS nos permite obtener un análisis mas completo. En la versión 15 de SPSS para realizar este análisis pulsamos Analizar à Comparar medias à Prueba T para dos muestras independientes. En nuestro caso los resultados son los siguientes:
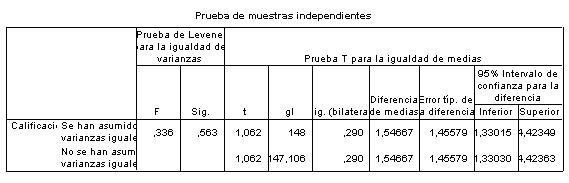
La tabla de resultados de SPSS nos muestra las dos posibles condiciones que se pueden dar en relación a la varianza, que sean iguales o no. En nuestro caso el estadístico de Levene toma el valor 0,336 y su valor p (también conocido como significación estadística) toma el valor 0,563 esto nos dice que se puede asumir el supuesto de igualdad de las varianzas de las dos muestras. Este mismo resultado ya lo obtuvimos con Excel cuando empleamos la prueba F de comparación de varianzas. El valor del estadístico t es el que ya habíamos obtenido con anterioridad t = 1,062 y su valor p es 0,29, valor que ya nos dio Excel. Pero además nos da el intervalo de confianza que comprende la diferencias de medias para poder aceptar la hipótesis nula, y nos dice que la diferencia estará comprendida entre los valores -1,33015 y 4,42349, y dado que la diferencia entre las dos medias es de 1,54667 y este valor se encuentra dentro del intervalo de confianza, también nos permite aceptar que las medias de ambas muestras son estadísticamente iguales, o lo que es lo mismo, no se han encontrado diferencias estadísticamente significativas entre las dos muestras en lo referente a su media.
Para concluir debemos dar respuesta a nuestra hipótesis de trabajo, que se preguntaba si había diferencias en cuanto a formación entre los alumnos de las universidades A y B. Los resultados han mostrado que no hay diferencias estadísticamente significativas en cuanto al nivel de conocimiento de la estadística entre las dos universidades, y las diferencias que se aprecian parecen estar provocadas por efectos del azar.
Conclusión final.
De los tres métodos de inferencia estadística existentes probabilidad del estadístico, región en que se encuentra el estadístico, e intervalo de confianza, solo uno, la región en que se encuentra el estadístico, lo podemos determinar sin el uso de un ordenador de manera sencilla. Precisamente este método inferencial es el que no nos ofrece SPSS de manera directa, pero dado que SPSS nos da los grados de libertad solo tenemos que asignar un alpha (generalmente 0,05), y podemos con estos datos usar Excel para conocer el valor (si es unilateral) o valores (si es bilateral) críticos.
*Análisis de datos: las funciones de análisis de datos de Excel en la versión 2003 no se instalan de manera ordinaria cuando se instala Excel normalmente. Para instalar las funciones de análisis de datos pulse en Herramientas à Complementos y seleccione Herramientas para análisis.
REFERENCIAS
COMENTARIOS
Publica tu comentario sobre este artículo
Ayuda
Publicado por Julieth . Fecha: 17-12-2013 21:22.
Yo tengo una duda, el calculo para una hipotesis unilateral en excel se realiza de la misma forma que para una hipotesis bilateral o hay alguna diferencia
MUY BUEN POST
Publicado por Dasaev. Fecha: 17-08-2013 05:12.
Excelente explicación, lo que muchos libros no te dicen, Gracias!!
SOBRE LA PUBLICACIÓN
¿El artículo ha sido revisado? NO
Sobre el autor
- Nombre de usuario: ant123
- Formación: Máster
- Enviar mensaje al autor
- Fecha de publicación: 14-07-2011 20:32
- Actualice este artículo (Solo puede hacerlo su autor).
- Fecha de actualizacion: 24-02-2012 19:12